ResourcesHub 学习资料共享平台
1. 创意来源
在学校的学习生活中,经常会遇到重要学习资料无法找到的情况,如考试往年题、上课PPT、保研加分政策资料等等,这些资料有时候只能靠微信上私信的传播,一定程度上地阻碍了同学的学习,也在某些方面造成了一定的“信息差”。
所以做一个校园学习资源共享平台,可以使学生们便捷地获取急需的学习资料,对于提升校园学习生活的便捷程度、打破部分信息造成的不公平、提升学生们的学习效率有所帮助。
2. 程序简介
ResourcesHub是一款多用户校园学习资源共享平台的Web应用,目的是为用户打造便捷分享学习资源、学校资料等内容的平台,打破校园“信息差”。基本功能有支持用户上传、下载各类学习资料文件,并且增加评分、评论、举报、排行等社区化功能,同时接入大模型以支持AI文档摘要、标签自动生成等功能,便于搜索以及了解资料。
.png)
本项目使用Django框架作为后端,利用Python语言编写,前端使用Bootstrap框架,主要语言为HTML+CSS+JS,以及部分Django模板语言。总代码行数(除Django项目自带代码和下载的CSS框架)约为1000-1500行左右。
3. 需求分析与设计
本项目想要实现一个校园学习资源共享平台,首先最核心的功能是资源上传和展示功能。资源上传功能中,用户可以上传各类学习资料(PDF、Word、PPT、Excel等格式),系统自动进行文件类型识别、内容提取和AI智能标签生成。上传的资源会根据用户权限进行审核,支持哈希去重机制防止重复上传。
然后是资源展示功能,首页需要可以展示所有用户上传的资源,同时为了方便用户检索,也应该支持搜索和排序功能,用户在搜索框中输入相关关键词后,系统会在资源标题、摘要、AI标签、课程、学院等多个维度进行全文检索,并支持按时间、下载量、评分、文件大小等多种排序方式。同时在搜索界面可以选择不同的筛选条件,比如点击"系列"可查看相关资源集合。用户访问资源详情页后,除下载功能外,同时应该显示资源的详情信息供用户浏览,同时展示所有的评分、评论等内容。
对于一个校园多用户应用,同时应该加强社区交互功能,加强用户的上传和分享欲望,提高活跃度。首先建立积分系统,对于用户的上传、下载、评分等行为提供加减分,激励用户分享优质资源,形成良性循环。资源页面添加评分、评论功能,即用户可以对下载的资源进行1-10分的评分,系统自动计算平均分并更新排名,同时支持文字评论功能,形成用户间的交流互动。添加排行页面,展示用户积分排行榜、资源贡献排行榜、热门下载排行榜等多个维度的统计信息,激发用户参与积极性。添加个人中心,展示用户的上传资源、下载记录、积分变动、个人统计等信息,支持用户查看自己的平台使用情况,以及对于优质上传者提供集中统一展示机会。
结合AI时代的到来,本项目添加了一些智能化功能。首先,资源的检索很难完全匹配(如:“数据结构往年题”搜索词与“数据结构2024期末试题”的资源),并且有时候用户的上传并未描述清楚资源的详情以及内容,导致用户下载者大量浪费时间。所以本项目添加了AI智能内容分析功能,通过OpenAI API对上传的文档进行智能摘要生成和标签提取,提升资源的可发现性和用户体验,用户的搜索词同时将与AI摘要、标签内容进行匹配,提升查找效率。另外在资源详情页面,添加“智能相关推荐”模块,基于当前浏览资源的标题相似度、课程匹配、AI标签相似度、学院相关性等多维度算法,为用户推荐相关学习资源,提升资源发现效率。
4. 总体思路与实现
后端使用Django框架进行开发,根据Django的MTV架构,主要完成项目的顺序为模型、视图和模板(也就是前端)。
在完成项目基本配置后,首先完成的是模型models.py,创建资源、评分数据、举报数据、下载记录、评论数据、用户资料等几个表,并添加各个字段和其变量类型、限制条件等。之后对于与模型相关的表单编写,为forms.py,对于前端用户提交的表单与模型字段联系并加以限制。以下是核心模型:
- Resource模型:存储资源基本信息、文件路径、AI分析结果
- UserProfile模型:扩展用户信息,包含积分、权限状态
- Rating模型:用户评分记录
- Comment模型:用户评论系统
- DownloadRecord模型:下载记录和积分流水
之后完成视图views.py部分,完成后端相关逻辑。视图部分主要是每个与路由绑定的函数,如index处理前端首页GET请求,并根据搜索、排序方式等内容完成排序,并将资源数据返回模板;评分、举报、评论等逻辑类似,将POST请求处理数据后存入数据库中持久化储存,返回错误信息或成功信息后重定向;还有比如下载等视图函数。另外添加的非路由关联函数存储于其他.py文件中,如处理AI请求的函数、抓取文件主要内容的函数,多函数写法可以让视图函数更加轻便直观。
最后是模板部分,利用的是Bootstrap前端框架作为样式,本地直接下载相关样式文件保存到静态文件夹,部署时改为使用cdn资源。主要分为以下页面:首页、资源页面、上传页面、个人主页、排行榜、注册登录页面。所有的页面套用base.html(引入基本css、js等)、navber.html(导航栏),页面的具体显示使用视图函数传回来的数据进行展示。
以下是项目核心页面与逻辑图:
graph TB
A[用户访问] --> B{是否登录}
B -->|否| C[注册/登录页面]
B -->|是| D[首页资源列表]
C --> E[用户注册]
E --> F[创建UserProfile<br/>分配初始积分5分]
F --> D
D --> G[搜索/浏览资源]
D --> H[上传资源]
D --> I[查看排行榜]
D --> J[个人中心]
%% 搜索流程
G --> K[输入关键词]
K --> L[多维度搜索<br/>标题/摘要/标签/课程]
L --> M[显示搜索结果]
M --> N[点击详情]
%% 上传流程
H --> O[选择文件]
O --> P[填写基本信息]
P --> Q[哈希去重检查]
Q -->|重复| R[提示文件已存在]
Q -->|不重复| S[文件类型识别]
S --> T[AI内容提取]
T --> U[调用OpenAI API]
U --> V[生成摘要和标签]
V --> W[保存到数据库]
W --> X[奖励积分50分]
%% 详情页流程
N --> Y[资源详情页]
Y --> Z[查看AI摘要]
Y --> AA[相关资源推荐]
Y --> BB[用户评论列表]
Y --> CC[下载按钮]
%% 推荐算法
AA --> DD[标题匹配算法]
DD --> EE[课程匹配算法]
EE --> FF[AI标签相似度]
FF --> GG[学院匹配算法]
GG --> HH[热度补充算法]
HH --> II[返回6个推荐资源]
%% 下载流程
CC --> JJ{是否作者本人}
JJ -->|是| KK[直接下载<br/>不扣积分]
JJ -->|否| LL{是否已下载}
LL -->|是| MM[直接下载<br/>显示重复提示]
LL -->|否| NN{积分是否足够}
NN -->|否| OO[提示积分不足]
NN -->|是| PP[扣除5积分]
PP --> QQ[作者获得4积分]
QQ --> RR[增加下载次数]
RR --> SS[创建下载记录]
SS --> KK
%% 评分评论流程
Y --> TT[评分1-10分]
TT --> UU[更新资源平均分]
UU --> VV[获得2积分奖励]
Y --> WW[发表评论]
WW --> XX[保存评论记录]
%% 排行榜流程
I --> YY[积分排行榜]
I --> ZZ[贡献排行榜]
I --> AAA[下载排行榜]
%% 个人中心流程
J --> BBB[查看个人信息]
J --> CCC[上传资源列表]
J --> DDD[下载记录]
J --> EEE[积分变动记录]
style A fill:#e1f5fe
style U fill:#fff3e0
style V fill:#fff3e0
style PP fill:#ffebee
style QQ fill:#e8f5e8
style VV fill:#e8f5e85. 技术学习
在完成本项目之前,我对于技术学习路线如下:
(1)在大一上学期《走进软件》课程中了解了基础的HTML+CSS+JS语法和编程,能够开发简单静态网页。
(2)暑假中预习了部分JAVA面向对象编程知识(但我的Java基础水平和Python水平差不多,且Python语法更简单些,也曾用过Python的OpenAI库,故选择以Python为基础的Django框架),课程:黑马程序员Java+AI智能辅助编程全套视频教程,java零基础入门到大牛一套通关_哔哩哔哩 bilibili。
(3)项目开始后的第一二天,学习了Django的项目开发和基本语法,学习课程【Python-Web开发】django快速入门网站开发bilibili,以及系统阅读菜鸟教程:Django 教程 | 菜鸟教程,完成学习笔记:Django 学习笔记 - Alex Li的学习笔记
(4)项目搭建至前端时,学习Bootstrap框架的语法:Bootstrap5 教程 | 菜鸟教程
6. 开发、运行环境和技术栈
开发环境:
本项目的实际开发环境为Windows 11系统,软件使用PyCharm 2025.2.0.1以及VS Code进行开发,本地Python版本为3.12.10,后端主要使用Django框架,开发环境Django版本为5.2.5。
部署环境:
部署于Linux服务器的Alibaba Cloud 3 (OpenAnolis Edition)系统上,Web服务器为Nginx 1.26.1,数据库为SQLite,Python版本为3.8,后端Django版本为4.2.24。
部署过程中开始时遇到了很多部署环境与开发环境不匹配的问题,以及Django无法持久化运行且无法直接访问静态文件的问题。所以服务端开发环境下必须使用Nginx作为网页服务器,并且Python版本要至少大于等于3.8,且pip版本处于最新,实际测试Python 3.7下无法使用,部分Python依赖库无法安装。
后端技术栈:
- 框架:Django
- 数据库:SQLite
- AI大模型:OpenAI API
- 文件处理:pdfplumber、python-docx、python-pptx等多种文档解析库
前端技术栈:
- 样式框架:Bootstrap 5.3.2
- 图标:Bootstrap Icons
7. 部署教程
下面给出本项目的部署教程,完整代码:https://github.com/lixu10/ResourceHub。
(1)部署环境要求:请参考第6节的要求,不低于所描述的部署环境版本即可安装
(2)修改配置文件:
ResourcesHub/settings.py:ALLOWED_HOSTS = ['localhost', '127.0.0.1']添加自己的域名;
resources/ai_request.py:在6-8行填入自己的AI配置信息;
(3)安装步骤:
// 进入项目目录
cd /yourmulu
// 创建虚拟环境:
python -m venv venv
source venv/bin/activate
// 安装依赖
pip install -r requirements.txt
// 迁移数据库
python manage.py makemigrations
python manage.py migrate
// 创建管理员账号
python manage.py createsuperuser
// 使用nohup后台运行,可修改默认端口(3024),此时即可通过ip+端口访问
pip install nohup
nohup gunicorn ResourcesHub.wsgi:application --bind 0.0.0.0:3024 &(4)使用Nginx服务器:配置文件如下,需自行修改部分信息
server {
listen 80;
server_name 你的域名或服务器IP;
# 静态文件路径
location /static/ {
alias /www/wwwroot/你的路径/static/;
}
# 媒体文件路径
location /media/ {
alias /www/wwwroot/你的路径/media/;
}
# 将所有其它请求代理给Gunicorn
location / {
proxy_pass http://127.0.0.1:3024; # 需要修改端口
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}(5)搭建完成,使用域名访问即可,默认后台地址/admin
8.关键技术与代码展示
(1)首页搜索和排序展示:
首页根据GET请求的参数获得搜索词q和排序方式sort,利用Q函数搜索过滤所有标题、学院、课程、标签、摘要中包含q的资源,然后根据sort参数确定排序方法,利用order_by函数进行排序,对于某个排序参数相等的情况,再根据创建时间排序,保证不会有相等元素。
def index(request):
q = request.GET.get('q', '').strip() # q为搜索参数
sort = request.GET.get('sort', 'new') # sort排序参数
rs = Resource.objects.exclude(status='removed') # 除下架的全部资源 rs
series_name = request.GET.get('series', '').strip() # 系列名字
# 处理搜索逻辑
if q:
# 在各个字段中搜索是否包含q
rs = rs.filter(
Q(name__icontains = q) |
Q(faculty__icontains = q) |
Q(course__icontains = q) |
Q(summary__icontains =q) |
Q(ai_summary__icontains = q) |
Q(ai_tags__icontains = q) |
Q(series__icontains=q)
)
if series_name:
rs = rs.filter(series = series_name) # 过滤系列
# 处理资源排序
if sort == 'new': # 最新
rs = rs.order_by('-created_at')
elif sort == 'download': # 下载次数
rs = rs.order_by('-downloads', '-created_at')
elif sort == 'size': # 文件大小
rs = rs.order_by('-size', '-created_at')
elif sort == 'look': # 查看次数
rs = rs.order_by('-looks', '-created_at')
else: # 得分
rs = rs.order_by('-rating_avg', '-created_at')
# Paginator分页器
paginator = Paginator(rs, 12)
page = request.GET.get('p', '1') # 页面,p为页码参数
now_page = paginator.get_page(page) # 当前页面的对象
return render(request,"index.html", {
'resources': now_page.object_list,
'now_page': now_page,
'q': q,
'series': series_name
})(2)上传文件去重、AI摘要等功能:
上传时包含保存表单、上传文件、去重、AI摘要等功能。首先保存表单数据为new_resources但不请求保存数据库,上传文件,第一步先进行hash去重,并用.chunks()函数切块计算,节约内存,对于hash256重复文件去除后再进行其他操作,避免浪费资源。保存相关字段后,先对文件类型进行判断,若可抓取内容则使用ai_extract函数抓取内容,不可以则利用表单信息完成提示词,拼装提示词后调用ai_generate函数生产摘要、标签,保存到数据库,再处理积分等操作。
@login_required()
def upload(request):
if request.method == 'POST':
form = UploadForm(request.POST, request.FILES) # 表单对象
if form.is_valid():
new_resources = form.save(commit=False) # 创建对象,不上传
new_resources.author = request.user # 先保存上传者
f = request.FILES.get('file') # 上传文件
# hash去重
hx = hashlib.sha256()
for chunk in f.chunks():
hx.update(chunk) # 切块计算sha256值,节省内存
new_resources.hash = hx.hexdigest() # 存储哈西加密结果
whether_same = Resource.objects.filter(hash = new_resources.hash).first() # 查找是否有相同哈希值
if whether_same: # 处理相同文件
messages.warning(request, f"您上传的文件{whether_same.name}系统中已经存在了,上传时间:{whether_same.created_at}")
return redirect('detail', pk = whether_same.pk)
# 保存其他信息
new_resources.type = jiexi_file_type(f.name) # 文件类型
new_resources.size = f.size # 文件大小
# 判断用户组别,对应文件状态
if request.user.profile.status == 1:
new_resources.status = 'normal'
elif request.user.profile.status == 0:
new_resources.status = 'pending'
else:
new_resources.status = 'removed'
f.seek(0)
new_resources.file = f # 保存文件
new_resources.save() # 保存到数据库
# AI生成摘要逻辑
file_type = judge_filetype(f.name) # 获取文件类型
text = ""
# 如果文件类型可以被读,则调用抓取文件内容
if file_type in {
"pdf",
"docx",
"txt",
"md",
"pptx",
"xls",
"xlsx"
}:
text = ai_extract(new_resources.file.path, file_type)
else: # 如果无法抓取内容,则直接把用户输入都给它
text = f"(没有获取到文件内部内容,请使用下面的信息尽量完成任务,但不能编造,也不要在Summary中说自己没有文件内部信息的事情,可以写的简短一些)名称:{new_resources.name}\n"
if f.name:
text += f"文件名:{f.name}\n"
if new_resources.summary:
text += f"简介:{new_resources.summary}\n"
if new_resources.faculty:
text += f"资料所属的学院:{new_resources.faculty}\n"
if new_resources.course:
text += f"资料所属的课程:{new_resources.course}\n"
if new_resources.year:
text += f"资料的年份:{new_resources.year}"
# generate回复
ai_summary, ai_tags = ai_generate(
text,
new_resources.name
)
# 保存到数据库
if ai_summary:
new_resources.ai_summary = ai_summary
if ai_tags:
new_resources.ai_tags = ai_tags
new_resources.save(update_fields=['ai_tags','ai_summary'])
add_point(request.user, 50) # 增加积分
messages.success(request, f"上传成功!文件名:{new_resources.name},已为您添加50积分")
return redirect('detail', pk = new_resources.pk)
else:
messages.warning(request, "bur哥们,你是不是没传文件?")
else:
form = UploadForm()
return render(request, 'upload.html', {'form': form})(3)资源详情页面相关智能推荐:
此处对于当前资源的关联资源进行匹配,只显示三个,匹配顺序为完整标题、课程、标签相同数量、学院、(下载量)。首先创建related_resources数组储存查到的资源,利用excluded_id数组储存本资源id和已匹配的资源以免重复。对于标题、课程、学院匹配的过程相同,先用filter筛选匹配的所有资源,再按照顺序添加到related_resources中;根据标签相同数量多少查找没有相应函数,开始时直接获取所有资源然后每一个遍历计算匹配Tags数量,时间复杂度较高,后来改为先用filter过滤出至少含一个相同Tags的资源,且用only只获取关键字段,减少资源消耗,再计算每个相同标签数,优化了时间复杂度。
python # 相关资源推荐部分 related_resources = [] #存储相关的资源,最大三个 excluded_ids = [resource.id] # 排除的资源,先排除当前资源 # 优先匹配相同标题 if resource.name and len(related_resources) < 3: similar_title = Resource.objects.filter( name=resource.name ).exclude(id__in=excluded_ids).exclude(status='removed') [:3-len(related_resources)] #匹配完全相同标题 for res in similar_title: if res.id not in excluded_ids and len(related_resources) < 3: related_resources.append(res) excluded_ids.append(res.id) # 匹配相同课程 if len(related_resources) < 3 and resource.course: course_resources = Resource.objects.filter( course=resource.course ).exclude(id__in=excluded_ids).exclude(status='removed') [:3-len(related_resources)] for res in course_resources: if res.id not in excluded_ids and len(related_resources) < 3: related_resources.append(res) excluded_ids.append(res.id) # 匹配相关标签 if len(related_resources) < 3 and resource.ai_tags: tags = [tag.strip().lower() for tag in resource.ai_tags.split(',') if tag.strip()] if tags: # 创建过滤条件 tag_query = Q() for tag in tags: tag_query |= Q(ai_tags__icontains=tag) # 获取含标签资源 candidate_resources = Resource.objects.filter( tag_query ).exclude(id__in=excluded_ids).only('id', 'ai_tags', 'name', 'downloads', 'rating_avg').exclude(status='removed') tag_resources = [] # 储存标签和相似度 for res in candidate_resources: if res.ai_tags: res_tags = [t.strip().lower() for t in res.ai_tags.split(',') if t.strip()] # 分割res标签 exact_matches = len(set(tags) & set(res_tags)) # 计算完全相同的标签数 if exact_matches > 0: tag_resources.append((res, exact_matches)) tag_resources.sort(key=lambda x: x[1], reverse=True) # 根据1第二个参数排序 for res, _ in tag_resources[:3-len(related_resources)]: if res.id not in excluded_ids and len(related_resources) < 3: related_resources.append(res) excluded_ids.append(res.id) # 匹配相同学院 if len(related_resources) < 3 and resource.faculty: faculty_resources = Resource.objects.filter( faculty=resource.faculty ).exclude(id__in=excluded_ids).exclude(status='removed') [:3-len(related_resources)] for res in faculty_resources: if res.id not in excluded_ids and len(related_resources) < 3: related_resources.append(res) excluded_ids.append(res.id) # 剩下是下载量最高的元素 if len(related_resources) < 3: popular_resources = Resource.objects.exclude(id__in=excluded_ids).order_by('-downloads').exclude(status='removed')[:3-len(related_resources)] for res in popular_resources: if res.id not in excluded_ids and len(related_resources) < 3: related_resources.append(res) excluded_ids.append(res.id)
9. 成果展示
本项目已完成部署,访问链接:http://resourcehub.2b.gs(不保证可访问)。
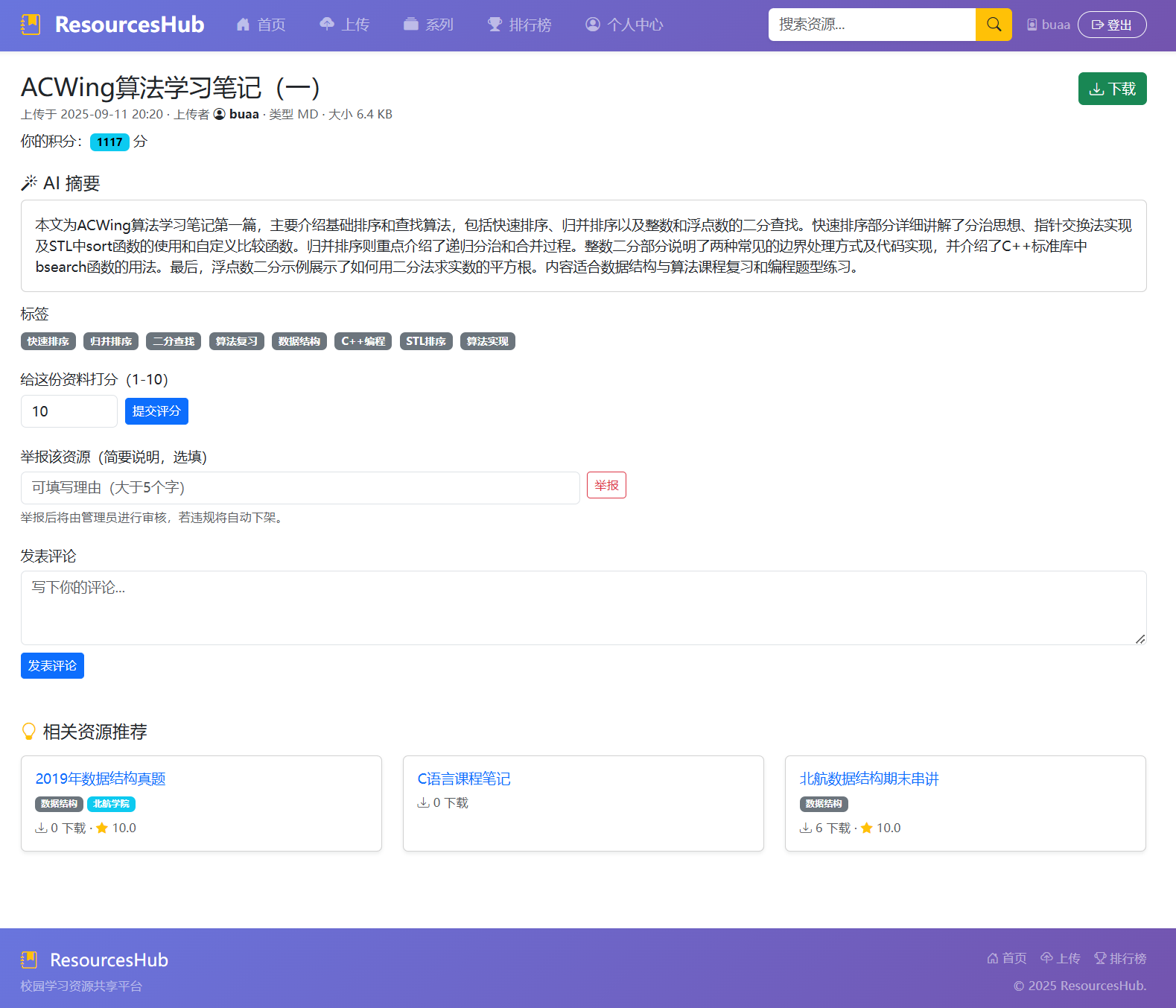
(1)资源详情页面:展示资源的各个详细信息,并提供下载链接,可以进行举报、评价、评论等功能,并推荐相关资源。
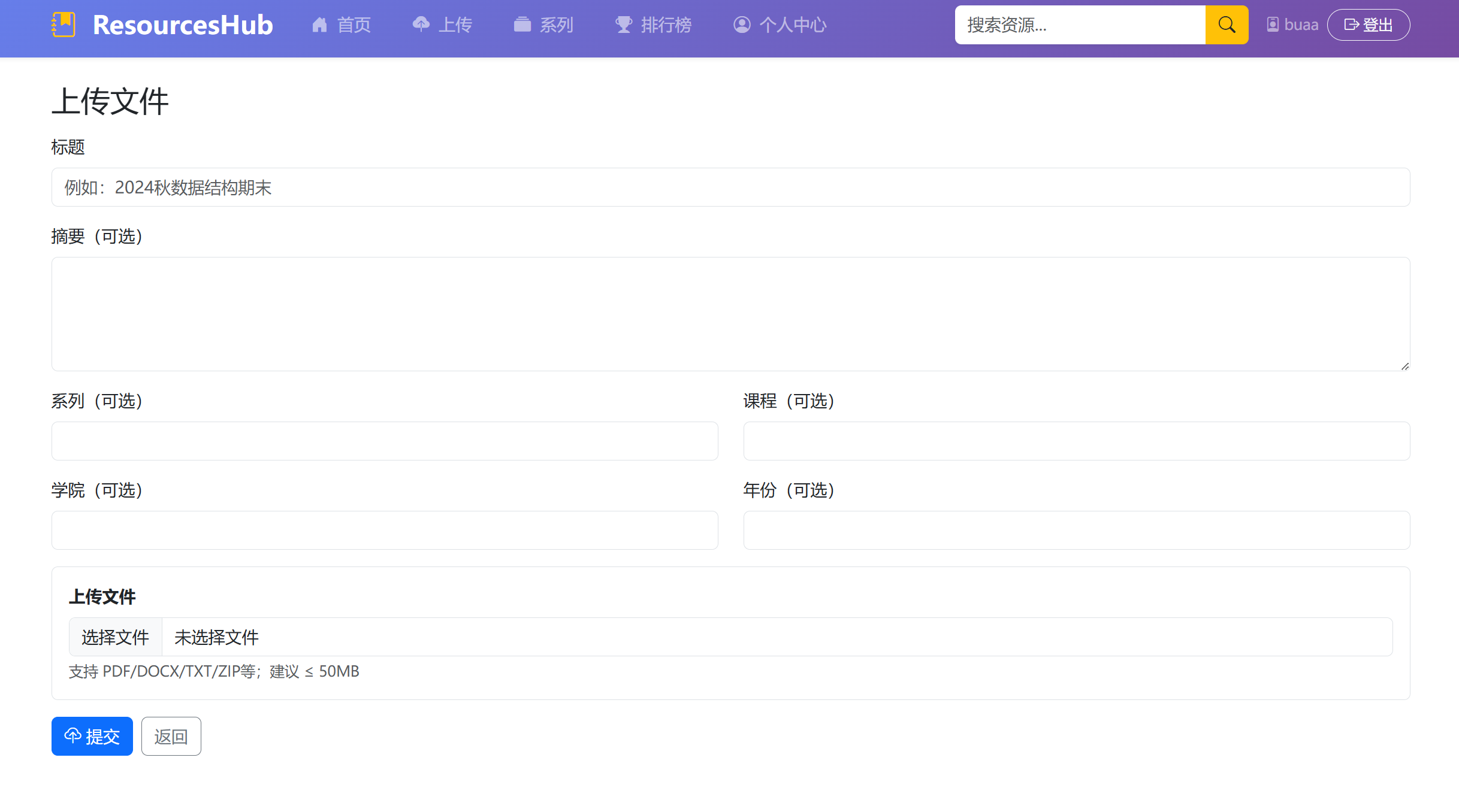
(2)上传文件功能:
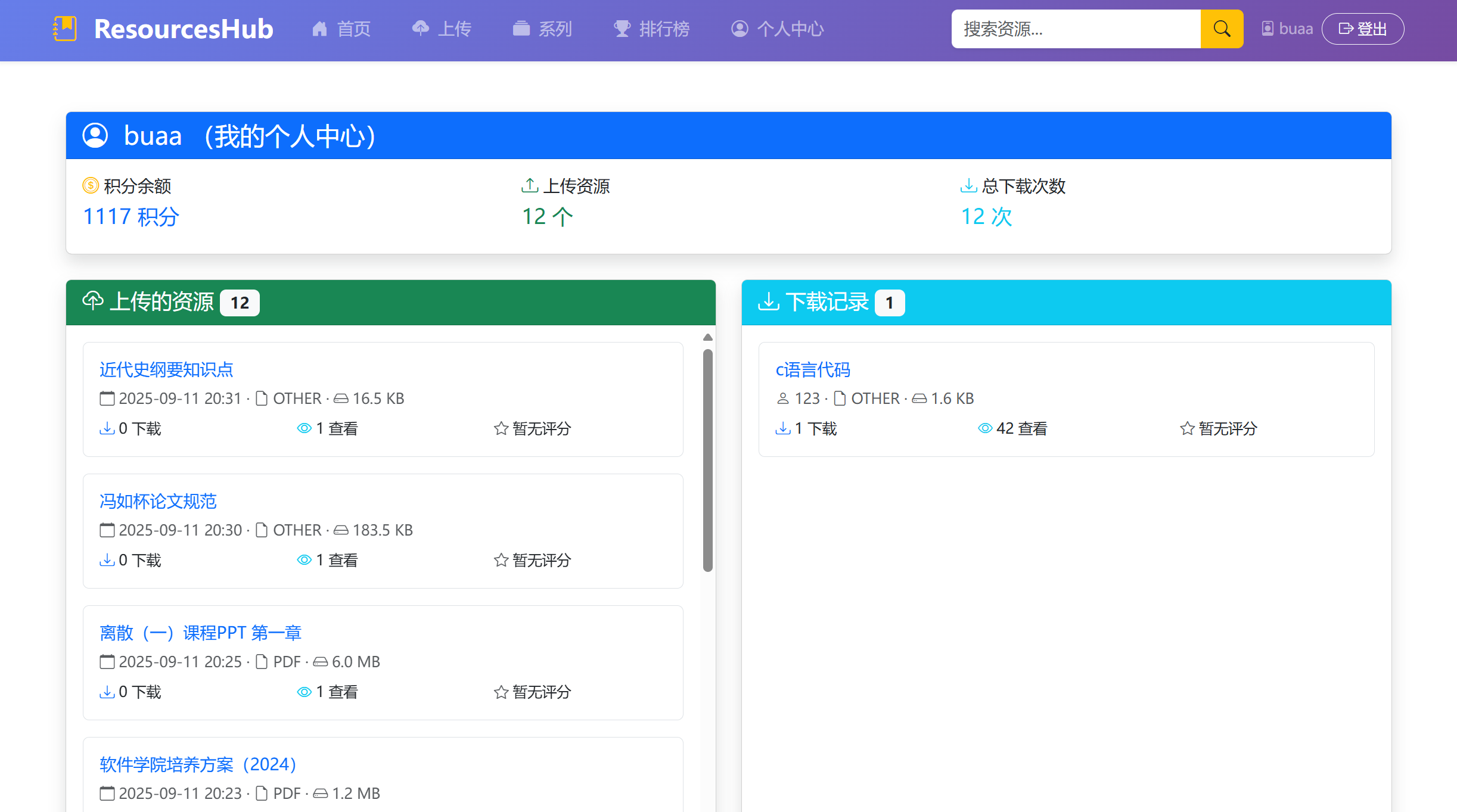
(3)个人中心页面:
10. 收获
(1)对于Django项目的基本框架和开发流程有了基本的了解,能使用Django框架完成简单的后端项目,了解了Django在数据库中增、删、改、查等的基本操作;
(2)对于OpenAI等Python库函数有了初步了解,比如能使用OpenAI API调用大模型;
(3)了解了Web开发中的基本思想,对于一些概念有了认识,比如路由配置、数据库调用、GET/POST请求等;
(4)更加熟练掌握了Python、HTML/CSS/JS、Django模板语言等编程语言,也了解一部分面向对象编程等课内知识;
(5)认识了开发环境、部署环境的区别,第一次使用命令行部署网站,有一定解决部署问题的能力;
(6)提升了我对于多文件项目开发的能力和解决实际问题的能力。